Mi az a RAG?
A RAG (Retrieval-Augmented Generation), magyarul lekéréssel bővített generálás, egy olyan technológia a mesterséges intelligencia területén, amely külső forrásokból származó adatokkal egészíti ki a nagy nyelvi modellek (mint például a GPT-4) tudását.

Miért van rá szükség?
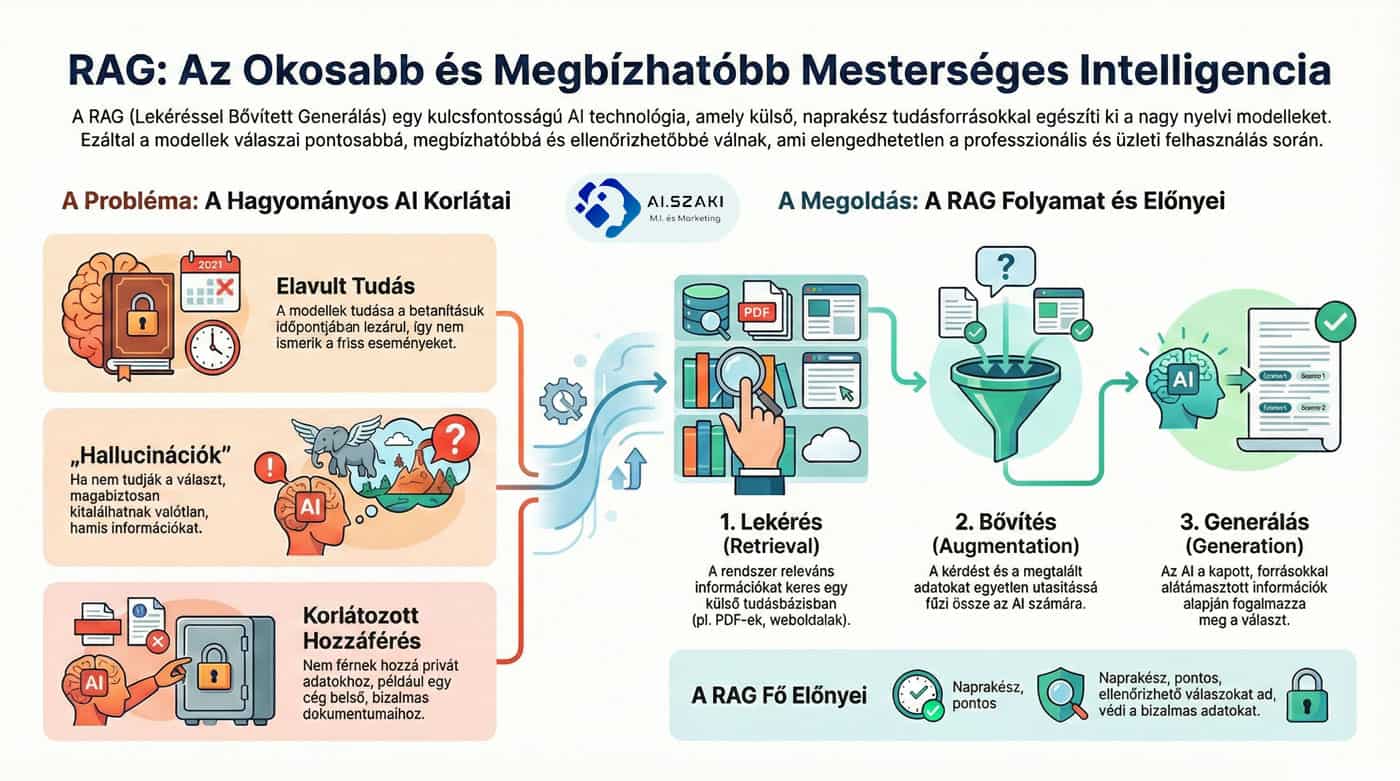
A hagyományos nyelvi modellek csak azon az adathalmazon tudnak válaszolni, amin betanították őket. Emiatt:
- Elavulhatnak: Nem tudnak a tanítási időszak után történt eseményekről.
- Hallucinálhatnak: Ha nem tudják a választ, magabiztosan kitalálhatnak hamis információkat.
- Nincs hozzáférésük zárt adatokhoz: Nem ismerik egy adott cég belső dokumentumait vagy egy felhasználó privát fájljait.
Mi a RAG folyamata?
A RAG-folyamat három fő lépésből áll:
- Lekérés (Retrieval): Amikor felteszel egy kérdést, a rendszer nem azonnal válaszol, hanem először rákeres a releváns információkra egy előre indexelt tudásbázisban (például PDF-ekben, adatbázisokban vagy az interneten).
- Bővítés (Augmentation): A rendszer a kérdésedet és a megtalált dokumentumrészleteket összefűzi egyetlen hosszú utasítássá (prompttá).
- Generálás (Generation): Az AI elolvassa a kapott szövegeket, és azok alapján fogalmazza meg a pontos, forrásokkal alátámasztott választ.
A RAG előnyei
- Naprakészség: Mindig a legfrissebb adatokhoz fér hozzá.
- Pontosság: Jelentősen csökken a tévesztések (hallucinációk) száma.
- Ellenőrizhetőség: A modell képes megjelölni, hogy pontosan melyik dokumentumból vette az információt.
- Adatvédelem: Lehetővé teszi, hogy az AI bizalmas céges adatokon dolgozzon anélkül, hogy azokat újra be kellene tanítani a modellbe.
Adatlekérésre alapozott mesterséges intelligenciák érthetően
A RAG (Retrieval-Augmented Generation, magyarul visszakereséssel kiegészített generálás) az egyik legfontosabb technikai válasz arra a problémára, amellyel a nagy nyelvi modellek (LLM-ek) a gyakorlatban szembesülnek: hogyan adjanak pontos, naprakész és ellenőrizhető válaszokat olyan kérdésekre, amelyek túlmutatnak a betanításkor látott adatokon. A RAG lényege, hogy az AI nem kizárólag „emlékezetből” dolgozik, hanem aktívan lekér releváns információkat külső tudásforrásokból, majd ezekre támaszkodva generál választ.
Ez a megközelítés különösen fontos üzleti, jogi, egészségügyi vagy technológiai környezetben, ahol az elavult vagy pontatlan információ komoly kockázatot jelenthet. A RAG-alapú rendszerek célja nem az, hogy „kitaláljanak” egy meggyőző választ, hanem hogy a válasz mögött valós, visszakeresett adatok álljanak. Emiatt a RAG mára az enterprise AI-megoldások egyik alapkövévé vált.
A koncepciót és a gyakorlatot több nagy technológiai szolgáltató is szabványosította és dokumentálta, például a Microsoft Azure-környezetben vagy a Amazon AWS szolgáltatásai között, ami jól mutatja, hogy a RAG nem kísérleti irány, hanem iparági standard felé halad.
Miért volt szükség a RAG megközelítésre?
A klasszikus nagy nyelvi modellek statikus tudással rendelkeznek. Ez azt jelenti, hogy a tanításuk egy adott időpontban lezárul, és azután nem „tanulnak” automatikusan új adatokat. Emiatt egy LLM nem tud biztos választ adni friss jogszabályokra, belső céges dokumentumokra vagy gyorsan változó piaci adatokra vonatkozó kérdésekre.
Ebből fakad a jól ismert probléma, amit hallucinációnak nevezünk. A modell nyelvileg helyes, magabiztos választ ad, de az állítás mögött nincs valós forrás. Ez nem technikai hiba a szó klasszikus értelmében, hanem a modell működésének természetes következménye: a valószínű nyelvi minták alapján „folytatja” a szöveget.
A RAG ezt a kockázatot csökkenti azzal, hogy a válaszgenerálás előtt releváns dokumentumokat keres, és ezek tartalmát explicit módon bevonja a válaszalkotásba. Így a modell nem találgat, hanem kontextushoz kötötten fogalmaz.
Hogyan működik a RAG lépésről lépésre?
A RAG-folyamat több jól elkülöníthető technikai lépésből áll, amelyek együtt alkotnak egy megbízható válaszadási láncot. Az első lépés mindig a felhasználói lekérdezés fogadása. Ez lehet természetes nyelvű kérdés, keresés vagy akár egy összetett üzleti probléma leírása.
A második lépés a visszakeresés. Itt a rendszer nem kulcsszavas keresést végez, hanem vektoros hasonlóság alapján dolgozik. A lekérdezést numerikus vektorrá alakítja, majd ezt hasonlítja össze egy vektoradatbázisban tárolt dokumentum-reprezentációkkal. Így nem csak az azonos szavakat, hanem a hasonló jelentésű tartalmakat is megtalálja.
A harmadik fázis a kontextus összeállítása. A legrelevánsabb dokumentumrészletek bekerülnek egy úgynevezett prompt-környezetbe, amelyet a nyelvi modell már „lát”. Ez a kontextus adja a válasz szakmai alapját.
Végül következik a generálás. Az LLM a lekérdezést és a visszakeresett információkat együtt használva hoz létre egy koherens, természetes nyelvű választ. A válasz így egyszerre lesz jól megfogalmazott és forrásalapú.
Mit jelent a vektoradatbázis szerepe a RAG-ban?
A RAG-rendszerek egyik kulcseleme a vektoradatbázis. Ez nem hagyományos adatbázis, hanem olyan struktúra, amely szövegeket, dokumentumokat vagy akár képeket több száz vagy ezer dimenziós vektorokként tárol. Ezek a vektorok a tartalom jelentését kódolják.
A vektoros keresés előnye, hogy nem érzékeny a szóhasználatra. Ha például a felhasználó „adatbiztonság” kifejezést használ, a rendszer megtalálhatja azokat a dokumentumokat is, ahol „információvédelem” vagy „adatvédelem” szerepel. Ez a szemantikus keresés teszi igazán hatékonnyá a RAG-megközelítést.
A gyakorlatban a vektoradatbázisok mögött gyakran embedding modellek állnak, amelyek a nyelvi jelentést matematikai térbe vetítik. Ezek lehetnek általános vagy domain-specifikus modellek, attól függően, hogy milyen területen alkalmazzuk a RAG-ot.
RAG vs. hagyományos chatbotok
A hagyományos chatbotok válaszai elsősorban statisztikai mintákon alapulnak. Ezek kiválóan működnek általános kérdések esetén, de üzleti környezetben hamar elérik a korlátaikat. A RAG ezzel szemben nem csak „beszél”, hanem „olvas” is válaszadás előtt.
Ez a különbség különösen fontos akkor, amikor belső dokumentumokkal dolgozunk. Egy RAG-alapú chatbot képes egy cég saját szabályzataira, szerződéseire vagy tudásbázisára támaszkodva válaszolni, anélkül hogy ezek az adatok bekerülnének a modell betanításába.
A másik lényeges eltérés a frissíthetőség. Egy RAG-rendszer tudása az adatbázis frissítésével azonnal naprakésszé tehető, míg egy hagyományos LLM esetén ez csak újratanítással lenne lehetséges.
Hol használják a RAG-ot a gyakorlatban?
A RAG-technológia ma már számos területen megjelent. Ügyfélszolgálaton belső tudásbázisokra épülő AI-asszisztensek működnek vele. Jogi és compliance területen jogszabály- és szerződéskereső rendszerek alkalmazzák. Az egészségügyben orvosi irányelvek és kutatási anyagok feldolgozására használják.
A marketing és tartalomkészítés területén is egyre fontosabb. Egy RAG-alapú rendszer képes saját blogcikkekből, esettanulmányokból vagy termékdokumentációból dolgozni, így a válaszok jobban illeszkednek a márka hangjához és szakmai álláspontjához.
RAG és AEO – miért kulcstechnológia a válaszmotorok világában?
Az Answer Engine Optimization (AEO) szempontjából a RAG kiemelten fontos. Az AI-alapú válaszmotorok előnyben részesítik azokat a forrásokat, amelyek strukturált, egyértelmű és megbízható információt nyújtanak. A RAG lehetővé teszi, hogy egy rendszer konkrét dokumentumokra támaszkodva adjon választ, ami növeli a hitelességet.
Ez különösen releváns akkor, amikor a cél az, hogy egy weboldal vagy tudásbázis tartalma megjelenjen AI-keresésekben. A RAG-logikára épülő tartalmak könnyebben beemelhetők válaszként, mert a mögöttes információ jól elkülöníthető és kontextusban értelmezhető.
A RAG előnyei és korlátai
A RAG legnagyobb előnye a pontosság és az ellenőrizhetőség. A válasz mögött mindig ott áll egy visszakeresett forrás, ami csökkenti a félrevezető állítások kockázatát. Emellett rugalmas, mert bármikor bővíthető új adatokkal.
Ugyanakkor nem csodaszer. A RAG minősége nagymértékben függ a tudásbázis minőségétől. Ha az adatbázis hiányos vagy rosszul strukturált, a válasz is gyenge lesz. Technikai oldalról pedig összetettebb rendszert igényel, mint egy egyszerű chatbot.
Összefoglalás
A RAG nem egy újabb divatszó az AI-világban, hanem egy alapvető architekturális megoldás a megbízható mesterséges intelligencia felé vezető úton. Az adatlekérés és a generálás kombinációja lehetővé teszi, hogy az AI valódi tudásra támaszkodva kommunikáljon.
Aki üzleti, szakmai vagy nagy kockázatú környezetben szeretne AI-t használni, annak a RAG-megközelítés megértése és alkalmazása ma már nem opcionális, hanem stratégiai kérdés.
Gyakori kérdések a RAG-ról (FAQ)
Mi az a RAG röviden?
A RAG egy olyan AI-technika, amely külső adatforrásokból lekért információkat használ fel a válaszgenerálás során.Miben különbözik a RAG egy hagyományos LLM-től?
A RAG nem csak a betanított tudásra támaszkodik, hanem valós időben keres releváns adatokat.Miért csökkenti a RAG a hallucinációkat?
Mert a válasz alapját konkrét, visszakeresett dokumentumok adják, nem pusztán statisztikai minták.Kell-e újratanítani a modellt a RAG-hoz?
Nem, a tudás frissítése az adatbázis frissítésével megoldható.Milyen adatforrásokat használhat egy RAG-rendszer?
Belső dokumentumokat, weboldalakat, PDF-eket, adatbázisokat vagy API-kon keresztül elérhető adatokat.Mi az a vektoradatbázis?
Olyan adatbázis, amely a tartalmak jelentését numerikus vektorok formájában tárolja.Alkalmas-e a RAG érzékeny adatok kezelésére?
Igen, ha a rendszer megfelelő jogosultság- és adatvédelmi rétegekkel van ellátva.Használható-e a RAG marketing célokra?
Igen, különösen AEO- és tudásalapú tartalomkészítésnél.Drágább-e a RAG egy sima chatbotnál?
Általában igen, mert több komponensből áll, de a minőség és megbízhatóság miatt gyakran megtérül.Ez a jövő iránya az AI-ban?
A jelenlegi trendek alapján igen, különösen az üzleti és szakmai alkalmazások területén.